Using Computer Vision in Helping the Deaf and Hard of Hearing Communities with Yolov5.
What would you do if you couldn’t hear anymore? What if you could only use your hands to communicate?

Simple tasks like ordering food, discussing financial matters at the bank, explaining your conditions at the hospital, or even talking to friends and family may seem daunting when they can no longer understand you.
Consider this..
The deaf community cannot do what most of the population take for granted and are often placed in degrading situations due to these challenges they face. Access to qualified interpretation services isn’t feasible in most cases leaving many in the deaf community with underemployment, social isolation, and public health challenges.
To give these members of our community a greater voice, I attempted to answer this question as my Data Science boot camp capstone project at General Assembly:
Can computer vision bridge the gap for the deaf and hard of hearing by learning American Sign Language?
If ASL can accurately be interpreted through a machine learning application, even if it starts with just the alphabet, we can mark a step in providing greater accessibility and educational resources for our deaf and hard of hearing communities.
Self reflection and why I chose this project
In my former profession I often would find and focus on problems, or inefficiencies in processes. When I brought up the point and created shortcuts in the form of Excel macros, I would suggest improvements in workflows and was often told:
“If it ain’t broke, don’t fix it!..”
As this was outside the realm of my job description of sales, I regretfully found myself in a hole for a long time often thinking to myself..
“but I can fix it..”
In short, I’ve buried good ideas and intentions long enough to people that wouldn’t listen to me. I had experienced a form of mental isolation before COVID-19, and it made me think about how much harder it must be for the deaf community. That is why I chose this project.
I had no idea if this would even work, but I wasn’t going to let the unknown stop me this time.
See the full capstone presentation here.
note — I genuinely hope that anyone reading this doesn’t stay stuck as long as I have, and takes the steps required to use your God given talents to its fullest!
Data and project awareness
The decision was made to create an original image dataset for a few reasons. The first was to mirror the intended environment on a mobile device or webcam. These often have resolutions of 720 or 1080p. Several existing datasets have a low resolution and many do not include the letters “J” and “Z” as they require movements.

The letter request form above was created with an introduction to my project along with instructions on how to submit voluntary sign language images with dropbox file request forms. This was distributed on social platforms to bring awareness, and to collect data.
Data warping and oversampling
A total of 720 pictures were collected for this project, and several were on my own hands due to time constraints. As this is a very small dataset, manual labeling with bounding box coordinates were made using the labelImg software, and a probability of transformations function was made to create several instances of the same image with changes in each image with adjusted bounding boxes.
Several choices in the types of augmentations were made from research that was done by Shorten, C., Khoshgoftaar. The paper can be found here.
Here is an example of what that looks like:

The data increased from 720 to 18,000 images after augmentations.
Modeling
Yolov5 by Ultralytics was chosen for modeling. This was released on June 10th of this year, and is still in active development. Even though this isn’t created by the original Yolo authors, Yolo v5 is said to be faster and more lightweight, with accuracy on par with Yolo v4 which is widely considered as the fastest and most accurate real-time object detection model.
90% of the augmented images were used for training, and 10% was reserved for validation. The model was trained for 300 epochs using transfer learning with the yolov5m pretrained weights.

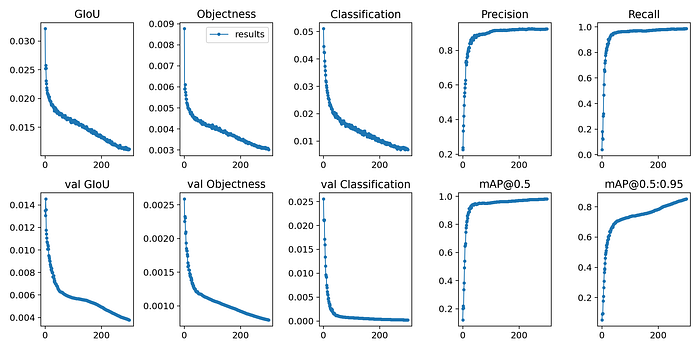
A mAP@.5:.95 score of 85.27% was achieved.
To understand mAP (Mean average precision) scores, you need to understand intersection over union (IoU). Basically, it’s the area of overlap between the actual bounding box and the predicted bounding box divided by the union of the two.
It gives us a confidence level in the prediction and counts the ones over a 50% confidence threshold. The mAP@.5:.95 score is the mean of these levels between 50% and 95% in steps of 5% which shows how well the object detection model performs in this dataset.
Image Inference tests
I had reserved a test set of my son’s attempts at each letter that was not included in any of the training and validation sets. In fact, no pictures of hands from children were used for training the model. Ideally several more images would help in showcasing how well our model performs, but this a start.

Out of 26 letters, 4 did not receive a prediction (G, H, J, and Z)
Letters that were incorrectly predicted were:
- “D” predicted as “F”
- “E” predicted as “T”
- “P“ predicted as “Q”
- “R” predicted as “U”
Time for webcam video tests that were recorded.
Video Inference tests
Here is another look at the video I posted at the top.
Even though several images were on my hand for training, the fact that the model was able to perform pretty well on such a small dataset, and still provide good predictions without feeling slow, is very promising!
More data will only help in creating a model that could be utilized in a wide variety of new environments.
As shown on the clip, even a few letters that were partially off screen had fairly good predictions.
Probably the most surprising thing is that the letters J and Z which require movements were recognized.
Other Tests
Left-handed:

================================
My son’s hand:

================================
Multiple instances:

================================
Limitations on the current model
I’ve discovered a few areas that can be improved on in future iterations of the model.
Distance:

================================
New Environments:

================================
Background Interference:
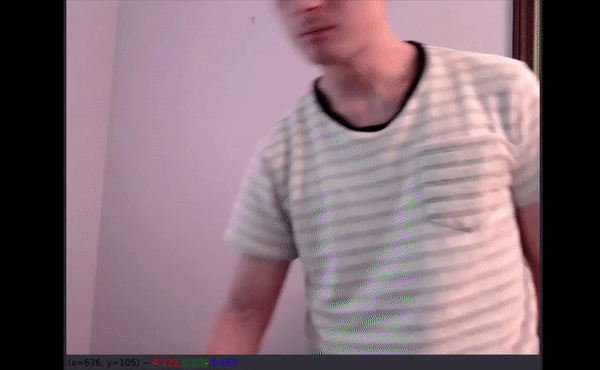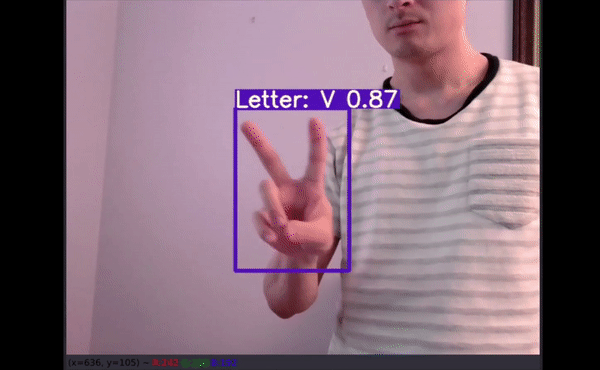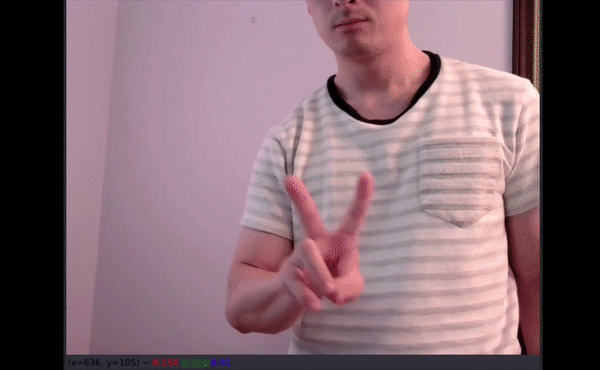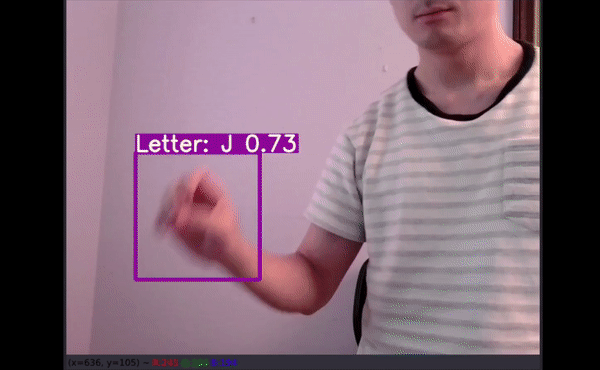
================================
Conclusions
Computer vision can and should be used in marking a step in greater accessibility and educational resources for our deaf and hard of hearing communities!
The fact that the model performs pretty well using only a small dataset cannot be ignored! Even in new environments with different hands it does a pretty good job at detection. There are a few limitations that can be addressed simply with more data to train on. With a few adjustments, and a lot more data, I expect a working model that can be expanded to far more than just the ASL alphabet.
Next Steps

I believe this project is aligned with the vision of the National Association of the Deaf in bringing better accessibility and education for this underrepresented community. If I am able to bring awareness to the project, and partner with an organization like the NAD, I will be able to gather better data on the people that speak this language natively to push the project further.
The technology is still very new, and there are some limitations on models that can be deployed on mobile devices. For my final project, I primarily implemented the Data Science process to find out if this can actually work. I’m really happy with the results and I’ve already trained a smaller model that I’ll be testing for mobile deployment in the future.
Final Remarks
I mentioned earlier in the article that I made the mistake of sitting on my ideas for years. I’ve been told once before “You are a dime a dozen” from a former boss letting me go for missing sales targets and I was convinced of my “lack of qualifications” for too long.
I’m grateful for the experience that General Assembly gave me in giving me confidence in my technical abilities and filling a personal gap of not finishing college many years back. I’ve graduated the program on Monday with some of the brightest people I’ve ever met, and I’m certain that I can finally use my gifts to make the world around me a little bit better.
What I’ve learned in this project is that computer vision can help our deaf and hard of hearing neighbors and give them the voice they deserve with technology that is available today.
If you have made it this far… Thank you… I’d love for you to share what I’m working on with your friends to hopefully make projects like this one my livelihood one day.
If you would like to get involved, or receive updates on this project, feel free to complete the embedded Google form I made below.
Resources
Yolov5 github
https://github.com/ultralytics/yolov5
Yolov5 requirements
https://github.com/ultralytics/yolov5/blob/master/requirements.txt
Cudnn install guide: https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html
Install Opencv: https://www.codegrepper.com/code-examples/python/how+to+install+opencv+in+python+3.8
Roboflow augmentation process: https://docs.roboflow.com/image-transformations/image-augmentation
Heavily utilized research paper on image augmentations: https://journalofbigdata.springeropen.com/articles/10.1186/s40537-019-0197-0#Sec3
Pillow library: https://pillow.readthedocs.io/en/latest/handbook/index.html
Labeling Software labelImg: https://github.com/tzutalin/labelImg
Albumentations library https://github.com/albumentations-team/albumentations
Link to my Github: https://github.com/insigh1/GA_Data_Science_Capstone
Special Thanks
Joseph Nelson, CEO of Roboflow.ai, for delivering a computer vision lesson to our class, and answering my questions directly.
And to my volunteers:
Nathan & Roxanne Seither
Juhee Sung-Schenck
Josh Mizraji
Lydia Kajeckas
Aidan Curley
Chris Johnson
Eric Lee
And to my General Assembly DSI-720 instructors:
Adi Bronshtein
Patrick Wales-Dinan
Kelly Slatery
Noah Christiansen
Jacob Ellena
Bradford Smith
This project would not have been possible without the time all of you invested in me. Thank you!
